FUNIX
Mettez un manchot dans votre PC
 Accueil
Accueil Linux
Linux Unix
Unix Téléchargement
Téléchargement[ Présentation
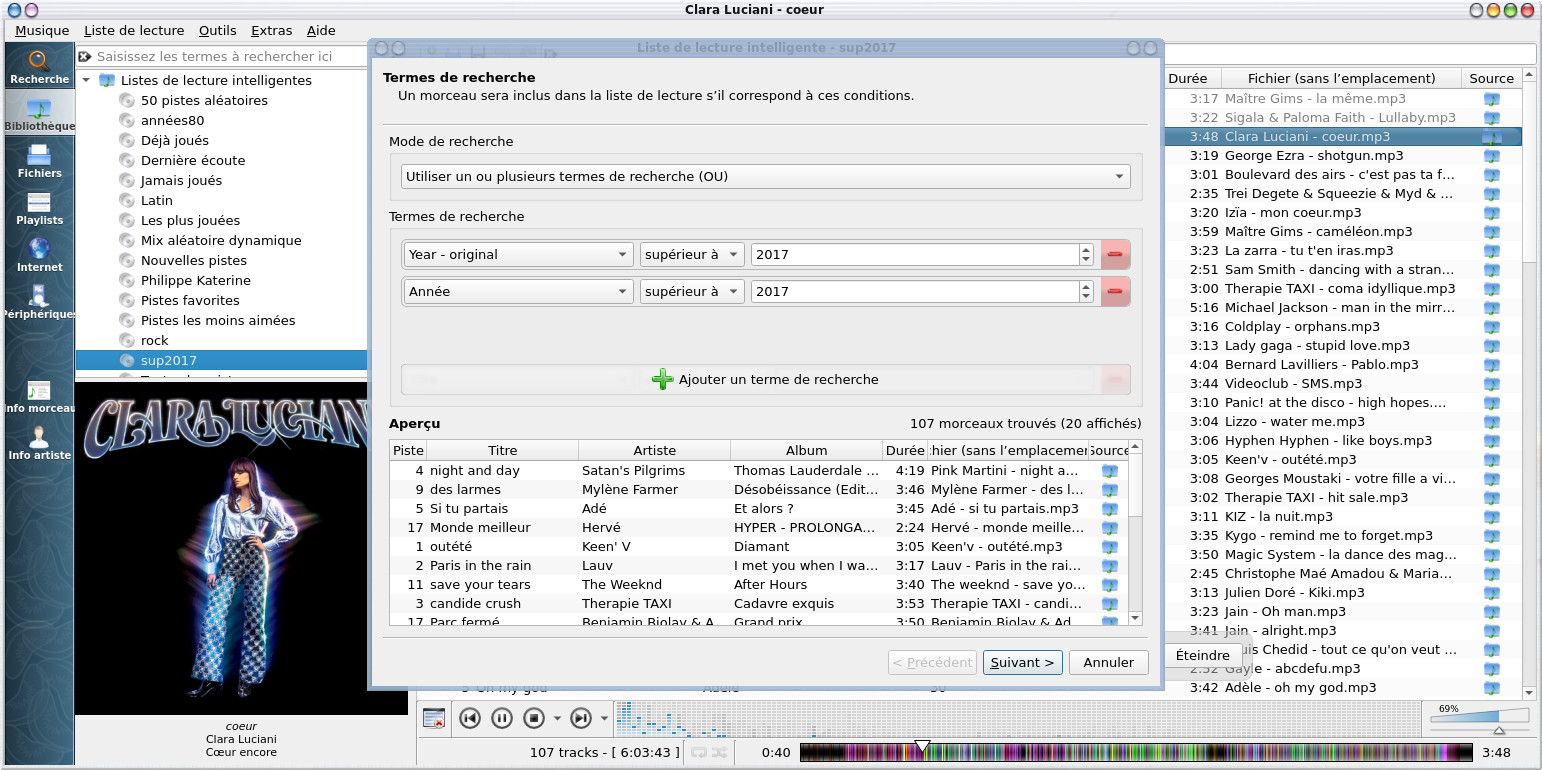
| Taguer ses fichiers audio ( Taguer
automatiquement avec MusicBrainz Picard , taguer
manuellement avec kid3 ) Gérer les listes de
lecture ( les formats de liste de lecture
, créer ses listes de lecture automatiquement
, créer ses listes de lecture manuellement
) ]
Gérer
les métadonnées et listes de lecture audio
Présentation
Taguer ses fichiers audio
Tout d'abord juste un petit mot sur le format des métadonnées audio. ID3 est de facto le standard utilisé pour les métadonnées audio qui signifie " IDentify an MP3", mais en fait il ne s'applique pas qu'aux fichiers MP3, cela marche également pour les fichiers FLAC ou OGG. Il se décline en plusieurs versions:- ID3v1: c'est la première version, où on retrouve le titre, l'artiste, l'album, l'année de parution, un commentaire et le genre musical
- ID3v1.1: idem avec le numéro de la piste sur l'album
- ID3v2: c'est beaucoup plus riche, on peut rajouter à peu près tout et n'importe quoi, en plus de l'image de l'album, on peut aller jusqu'aux paroles de la piste, le compositeur, l'arrangeur, etc. le champ ReplayGain fait son apparition, il donne le volume sonore de la piste et permet à un lecteur audio de normaliser le son. La dernière version de ce standard est la ID3v2.4 qui date de 2000.
- les tags APE qui existent dans les versions APEv1 et APEv2 dont on retrouvera ici la description de l'ensemble des champs, il a le défaut de ne pas embarquer d'image de l'album
- les tags vorbis qui peuvent être utilisés pour les fichiers audio Vorbis, FLAC, Theora et Speex, on retrouvera le format des différents champs par là
Dans tous les cas il faudra éviter le mixte de format de métadonnées rendu possible par le fait que les tags ID3 et APE peuvent se retrouver dans le même fichier au début et à la fin (et vice-versa), ça peut entraîner des conflits et des erreurs de lecture suivant le lecteur.
Taguer automatiquement avec MusicBrainz Picard
tar xvfz mutagen-release-1.47.0.tar.gz
python setup.py install
Sur le site de picard on récupère l’archive qu’on décompresse en tapant:
tar xvfz picard-2.10.tar.gz
cela donne le répertoire picard-2.10 dans lequel on tape en tant que root:
Il m’a paru utile de créer un compte sur le site MusicBrainz qui se définit comme une encyclopédie musicale libre qui collecte les métadonnées musicales que tout le monde peut alimenter et enrichir.
On lance picard en tapant simplement picard dans un shell. Dans les options, j’ai indiqué mon compte MusicBrainz, picard me renvoie ensuite sur le site et me donne un code d'activation que je dois saisir alors, au final cela donne cela
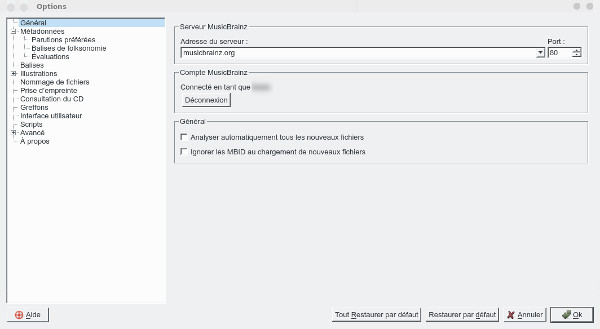
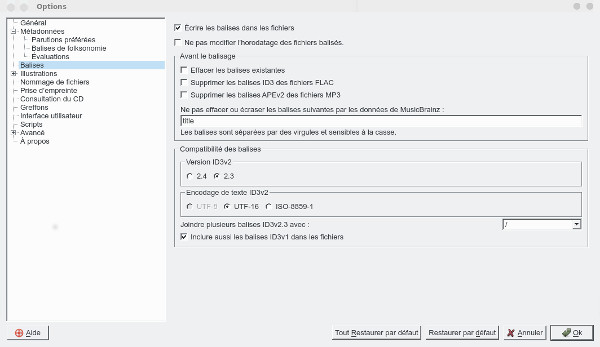
J'ai laissé les paramètres par défaut, ou presque, voici quelques pages de configuration intéressantes, tout d'abord sur le format des balises.
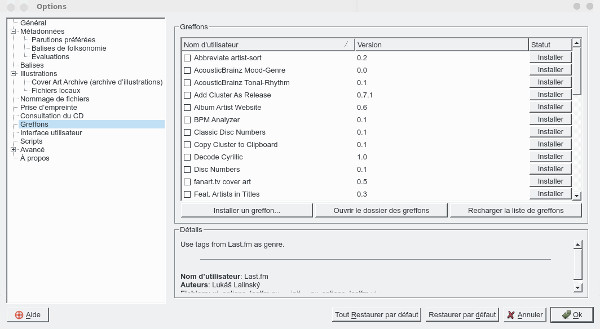
Sur cette page, on peut activer des greffons, pour l'instant je n'ai pas jugé utile d'en rajouter
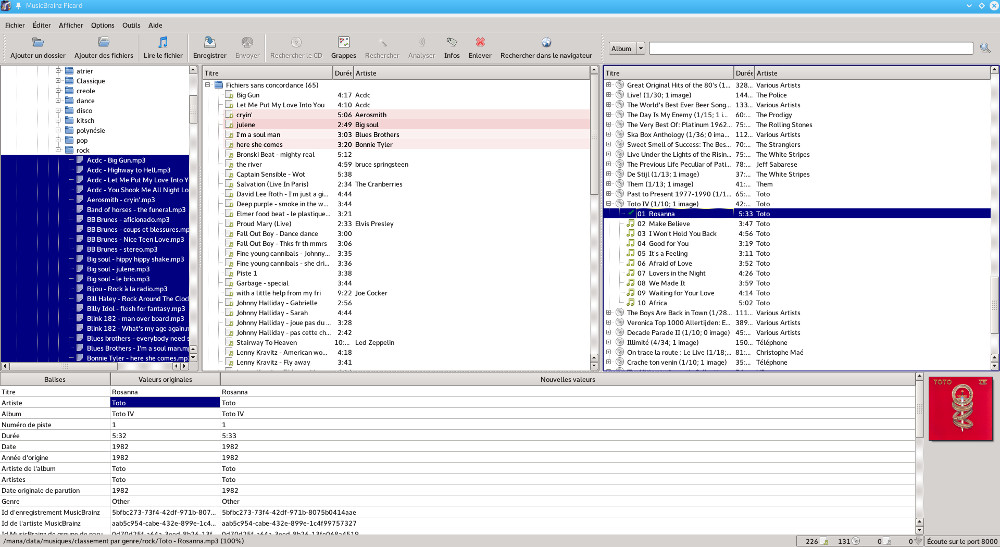
A gauche on se déplace dans l’arborescence, on sélectionne les titres à identifier qu’on glisse par drag and drog dans la colonne du milieu, par défaut tous les fichiers sont sans concordance. On les sélectionne et on clique sur Rechercher, picard va rechercher dans sa base les fichiers dont les balises correspondent le mieux aux nôtres, à droite on va voir apparaître tous les albums correspondants que picard aura trouvé. On peut regretter juste que pour beaucoup ce soit des albums de compilation qui apparaissent et non pas l’album d’origine, il y a également des faux positifs, une chanson qui est attribuée à quelqu'un d'autre, mais on verra plus loin comment traiter cela. Pour certains on aura un message impossible de charger l’album, pour résoudre cela il faut sélectionner les albums non chargés et avec le menu accessible par un clic droit choisir Rafraîchir, il ne faut pas hésiter à insister, ça se charge parfois au bout de 4 ou 5 fois. Il reste un certain nombre de fichiers dans la colonne du milieu sans concordance, il faudra à nouveau les sélectionner et faire plusieurs fois Rechercher, car curieusement il continue à identifier des fichiers alors qu’il ne l’avait pas fait auparavant. Pour ceux qu’il n’aurait pas identifié, ça peut venir d’un fichier pas bien balisé à la base ou mal nommé, dans ce cas vérifier et modifier les tags Artist et Title et recommencer. Au final il me reste souvent moins de 5% de fichiers non identifiés ce qui n’est pas énorme, on sélectionne les albums dans le bandeau à droite qui ont été trouvés et on enregistre la totale à partir du menu contextuel. Tous les fichiers vont être modifiés avec les bons tags en rajoutant également une image d’illustration et le tour est joué. Les albums et fichiers non sauvegardés apparaissent dans le bandeau à droite avec une petite étoile sur le disque.
Si vos fichiers sont mal balisés à la base, la recherche peut être plus laborieuse, il faut commencer par les baliser correctement. Ça peut être laborieux de modifier un à un les balise des fichiers, donc s’ils sont bien nommés du style mon artiste – mon titre.mp3. On dispose d’un outil bien pratique qui va faire ça automatiquement, on sélectionne les fichiers, puis on clique sur Outils->Baliser à partir des noms de fichier. Pour le style de nommage ci-dessus, on prendra %artist% – %title% qui permettra de taguer proprement le fichier et de lancer ensuite une recherche plus efficace. Si les fichiers correctement tagués n’ont toujours pas été identifiés, je vous encourage a minima de les enregistrer (sélection des fichiers dans le bandeau du milieu puis enregistrer à partir du menu contextuel.
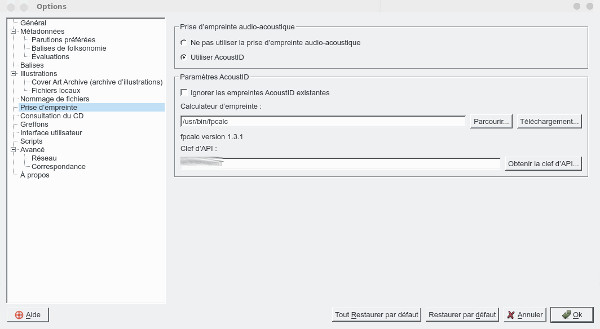
Quand la recherche devient infructueuse, on peut passer à la recherche à partir de leur signature acoutisque en cliquant sur Analyser, picard va calculter l'empreinte acoustique du fichier en la comparant avec celles présentes sur le serveur d'empreinte.
Pour les fichiers restants, on peut penser qu'ils ne sont pas dans la base de picard, on peut donc l'enrichir et en faire profiter la communauté avec les bonnes balises associées en sélectionnant la piste et en cliquant sur Envoyer AcoustIDs
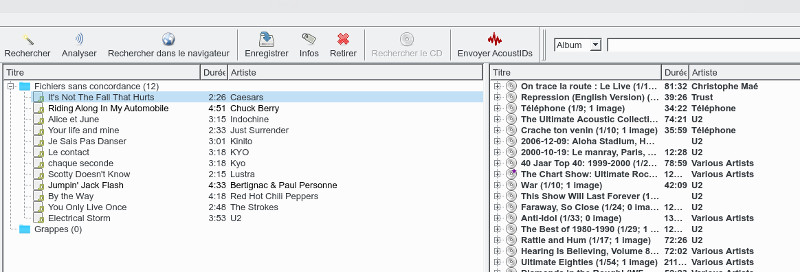
Vous aurez remarqué que picard classe les fichiers audio par album et non par artiste (par exemple), chaque fichier est rattaché à un album et l'image associée au fichier visible dans le lecteur audio est celle rattachée à l'album. Pour ma part mes mp3 sont rangés dans des répertoires par genre musical, quand je passe d’un répertoire à l’autre je quitte picard et je le relance pour partir d’un écran vierge sans albums préchargés. Dans la philosophie de picard, les fichiers sont classés de base par album, avec un répertoire par album, il faudra dans ce cas plutôt utiliser la fonction Grappes, cette page (en anglais) explique comment faire. En résumé, on sélectionne le répertoire album, on le glisse dans le bandeau du milieu et on clique sur l'outil Regrouper, l'album va se retrouver au niveau de l'arborescence Grappe dans le bandeau du milieu et de la même manière on va cliquer sur Rechercher ou Analyser pour trouver l'album correspondant.
Maintenant que faire des fichiers sans
concordance ? Il suffit de sélectionner le fichier correspondant dans le
bandeau du milieu puis avec le menu contextuel on choisit Rechercher
des pistes similaires
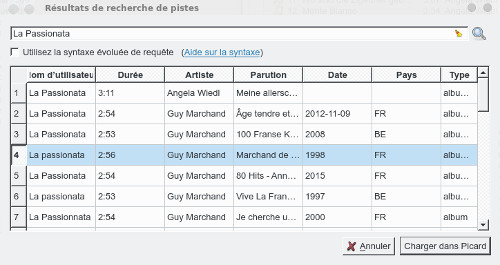
Autre méthode, on sélectionne la piste puis on clique sur Rechercher dans le navigateur, automatiquement on est renvoyé sur le navigateur qui affiche les pistes concordantes
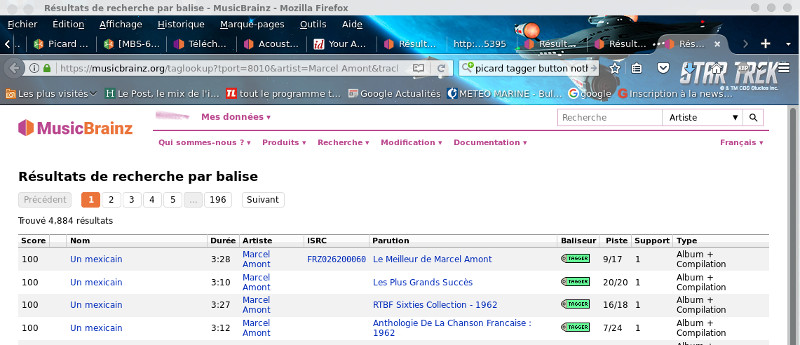

Pour les faux positifs du bandeau à droite, c'est à dire les fichiers qui ont été associés à des mauvaises pistes, dans le bandeau de droite on sélectionnera la piste dans l'album correspondante, et de la même manière à partir du menu contextuel on choisira Rechercher des pistes similaires.
On procédera de la même manière pour les pistes associées à des compilations si vous souhaitez les associer aux albums de l'artiste concerné.
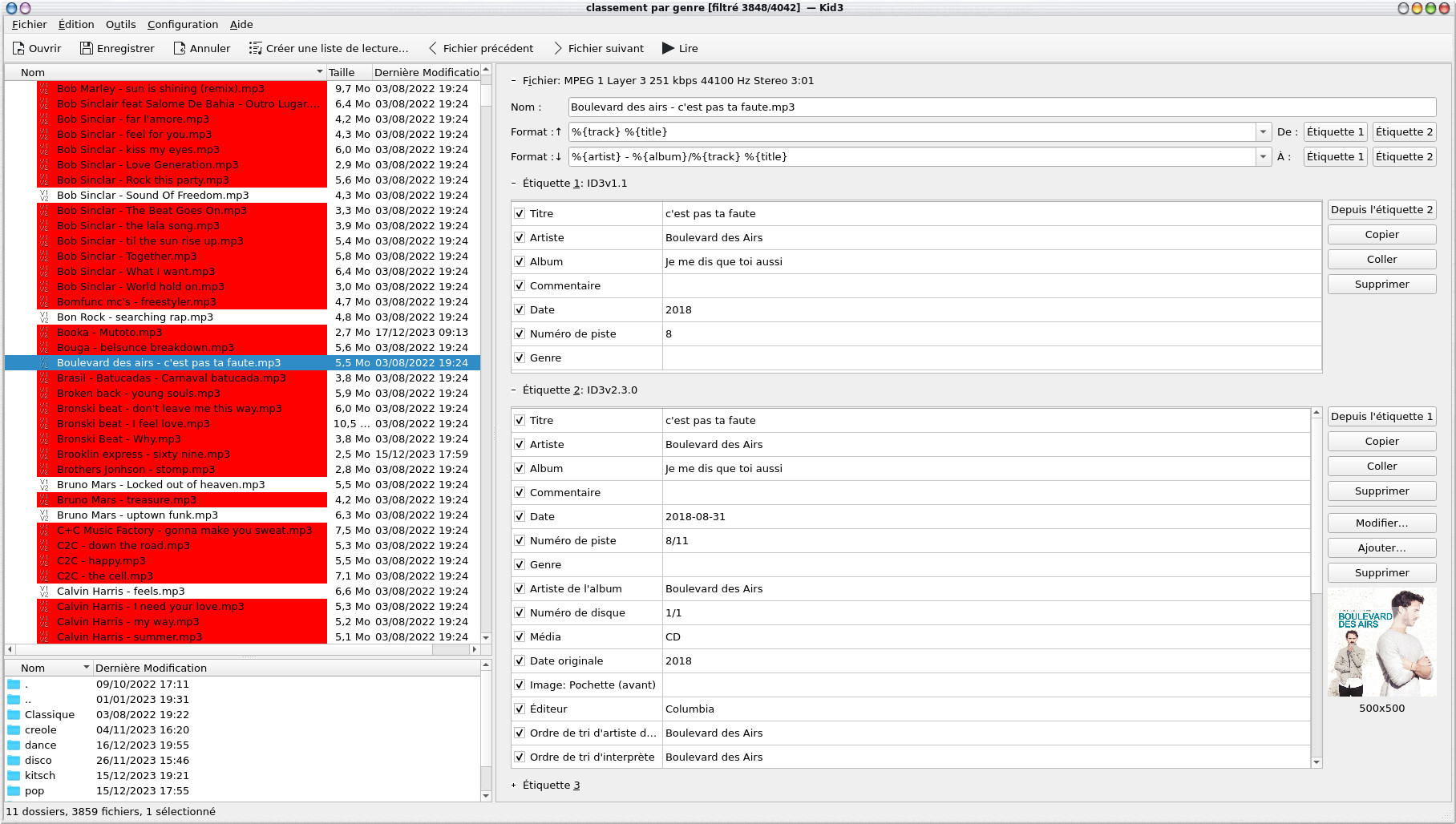
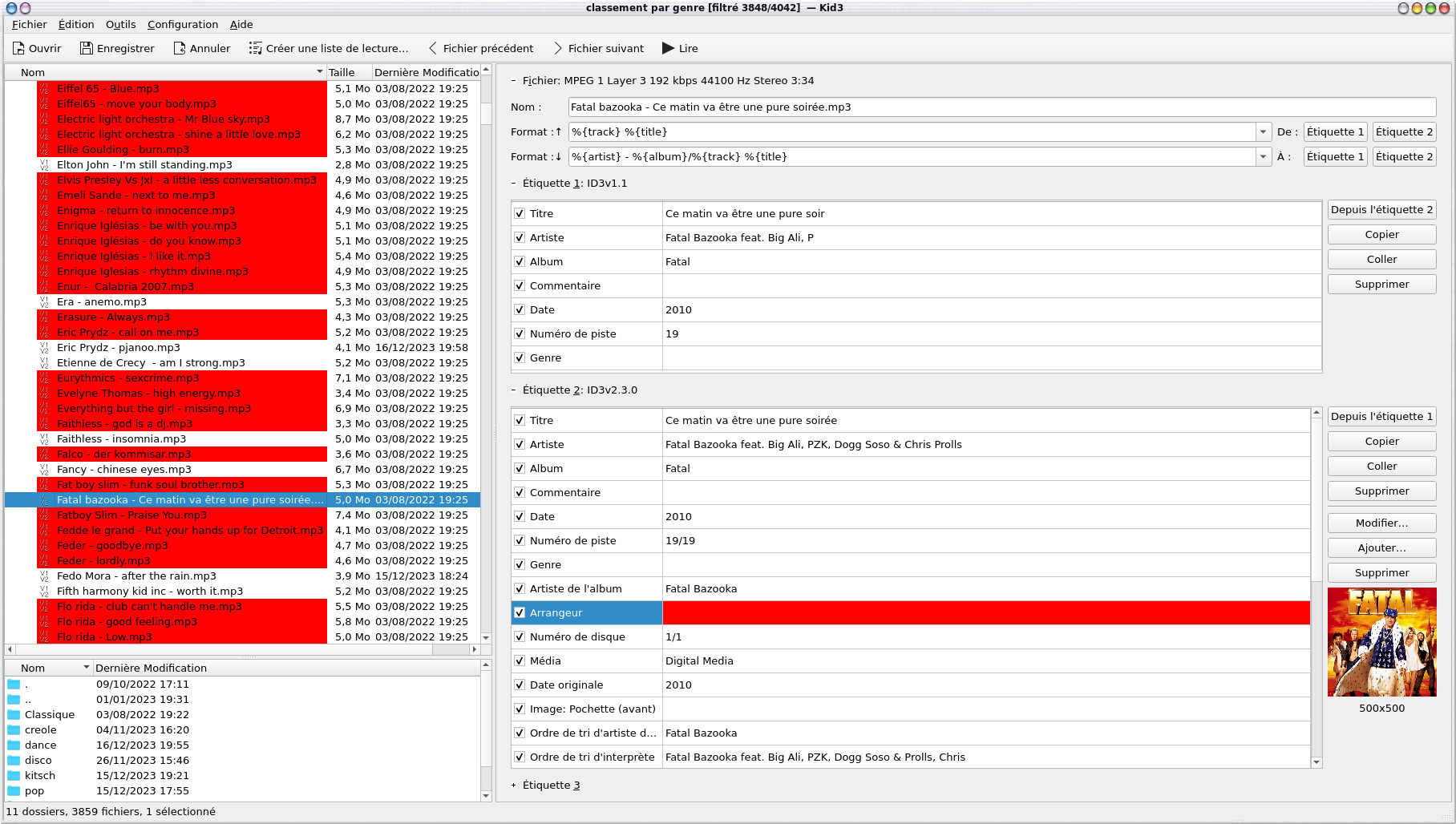
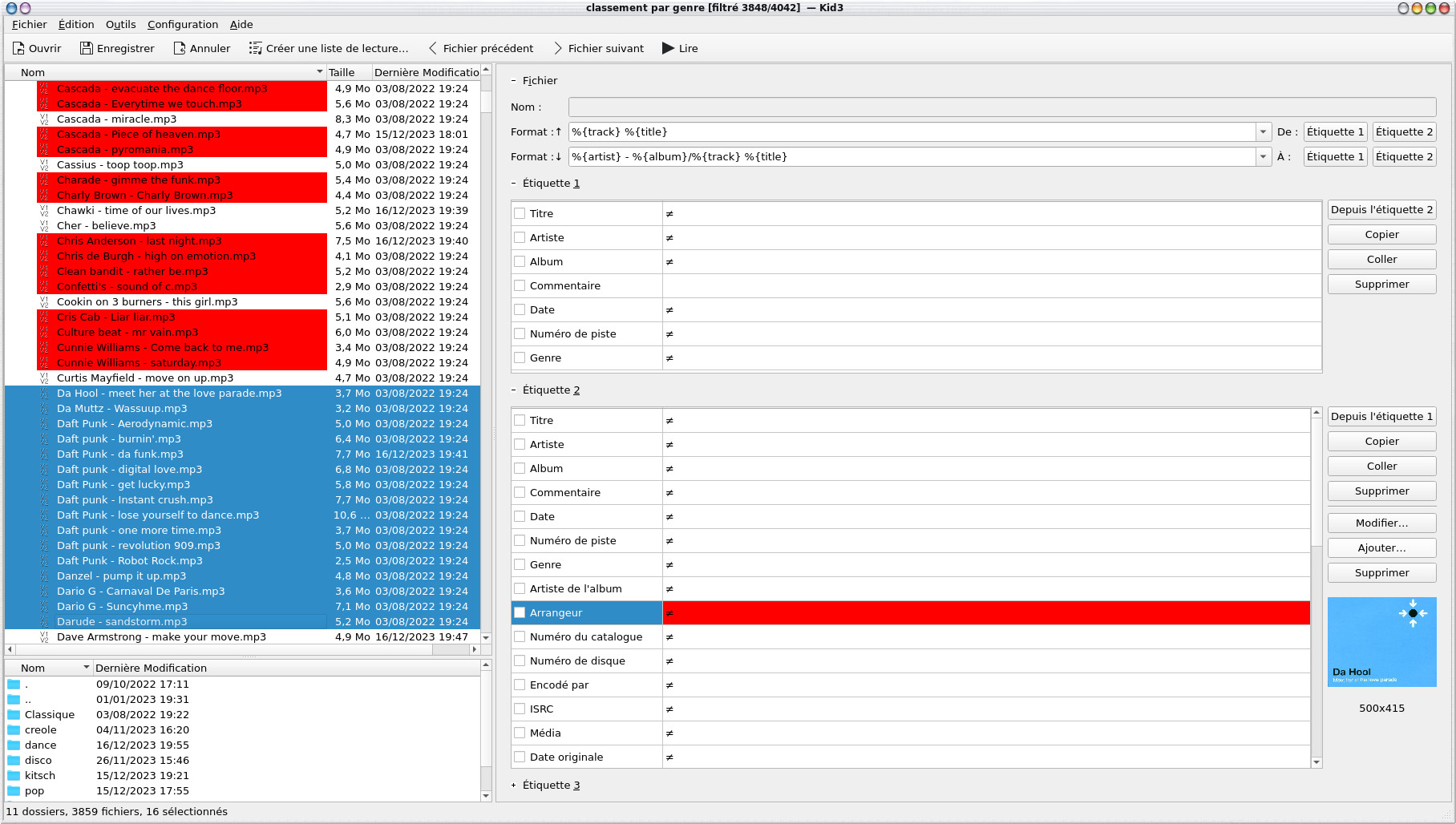
Une piste audio peut être identifiée par des tags ID3v1.1 et ID3v2.30, les informations sont évidemment bien plus riches avec la dernière version et les champs d'information plus long (notamment pour le nom des artistes et l'album), on y retrouve également l'image de l'album. Les champs des tags ID3v2.30, ils ont été remplis automatiquement par picard.
On notera qu'un certain nombre de pistes sont marquées en rouge, en fait c'est qu'elles ne respectent pas totalement le standard ID3. Si nous regardons la configuration, elles apparaissent car le champ "Marquer des violations de la norme" est coché par défaut.
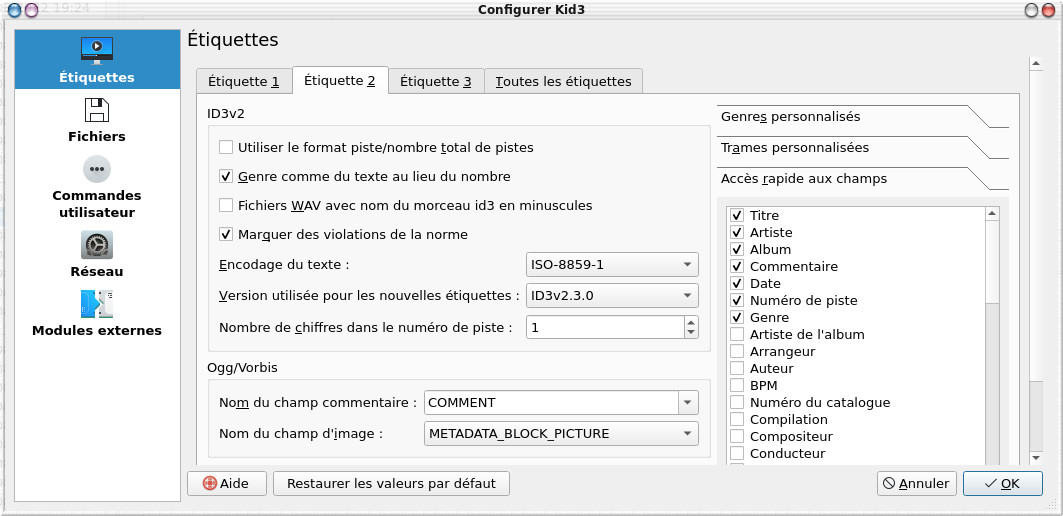
Par défaut on choisira aussi la version ID3v2.30 qui est mieux reconnue de la plupart des lecteurs que la v2.40 même si celle-ci date de 2000 !
pour le jeu de caractère, on a le choix entre
- l’ISO-8859-1, qui permet d’enregistrer presque tous les caractères du français ;
- l’ISO-8859-15, une variation de l’ISO-8859-1, qui rajoute le symbole « euro » et le « l’e dans l’o»
- l’UTF-8, qui permet théoriquement d’encoder toutes les langues, du français au japonais en passant par l’arabe.
Même si l'UTF-8 est à privilégier aujourd'hui, là aussi on préférera utiliser ISO-8859-1 qui reste encore le plus reconnu par les lecteurs audio.
- Chemin absolu vers le fichier
- Chemin relatif vers le fichier par rapport au fichier M3U
- URL d'un fichier distant
- #EXTM3U - placé en en-tête de fichier indiquant qu'on utilise le format Extended M3U
- #EXTINF : informations sur la piste
- #PLAYLIST : Le titre de la playlist
Voilà un exemple de fichier au format M3U étendu
#EXTM3U
#EXTINF:227,Roé - Soledad
/ultra/data/musiques/classement par genre/pop/Roe - soledad.mp3
#EXTINF:141,Al Martino - Volare
/ultra/data/musiques/classement par genre/pop/Al Martino -
Volare.mp3
#EXTINF:218,Nek - Laura non c'e
/ultra/data/musiques/classement par genre/pop/Nek and Cerena - Laura
non ce.mp3
(...)
/ultra/data/musiques/classement par genre/pop/Manu Chao - Bongo
Bong.mp3
#EXTINF:219,Gilberto Gil - Toda menina baiana
/ultra/data/musiques/classement par genre/pop/Gilberto Gil - Toda
Menina Baiana.mp3
#EXTINF:248,Umberto Tozzi - tu
/ultra/data/musiques/classement par genre/pop/Umberto Tozzi - tu.mp3
Le chiffre devant le nom de la piste est la durée de la piste en seconde.
<playlist version="1" xmlns="http://xspf.org/ns/0/">
<trackList>
<track>
<location>/ultra/data/musiques/classement par genre/pop/Roe - soledad.mp3</location>
<title>Soledad</title>
<creator>Roé</creator>
<album>Roé</album>
<duration>227000</duration>
<trackNum>1</trackNum>
<image>(embedded)</image>
</track>
<track>
<location>/ultra/data/musiques/classement par genre/pop/Al Martino - Volare.mp3</location>
<title>Volare</title>
<creator>Al Martino</creator>
<album>Best of Al Martino</album>
<duration>141000</duration>
<trackNum>1</trackNum>
<image>(embedded)</image>
</track>
<track>
<location>/ultra/data/musiques/classement par genre/pop/Umberto Tozzi - tu.mp3</location>
<title>tu</title>
<creator>Umberto Tozzi</creator>
<album>Tu</album>
<duration>248000</duration>
<trackNum>1</trackNum>
<image>(embedded)</image>
</track>
</trackList>
</playlist>
read -p "Chemin absolu ou relatif (par défaut relatif) " chemin
if [ "$chemin" = "absolu" ]
then
path=$(pwd)
else
path="."
fi
playlist="playlist.m3u"
rm -f $playlist
IFS=$'\n'
for fichier in $(find $path type f | grep '/*.ogg\|/*.mp3\|/*.flac')
do
echo "Fichier trouvé $fichier"
echo $fichier>>$playlist
done;
unset IFS
read -p "Genre musical : " genre
read -p "Chemin absolu ou relatif (par défaut relatif) " chemin
if [ "$chemin" = "absolu" ]
then
path=$(pwd)
else
path="."
fi
playlist="playlist-$genre.m3u"
rm -f $playlist
IFS=$'\n'
for fichier in $(find $path type f | grep '/*.ogg\|/*.mp3\|/*.flac')
do
if ffprobe -loglevel quiet -hide_banner -show_entries format_tags=genre -of default=noprint_wrappers=1:nokey=1 $fichier 2>&1 | grep -i $genre ; then
echo "Fichier trouvé $fichier"
echo $fichier>>$playlist
fi
done;
unset IFS
read -p "Entrez le nom du fichier : " fichier
read -p "Entrez la chaine à remplacer : " chaine1
read -p "Entrez la chaine de remplacement : " chaine2
echo "Traitement de $fichier ..."
fichiertemp=$(basename "$fichier" | cut -d. -f1)
extension="${fichier##*.}"
sed "s|$chaine1|$chaine2|g" $fichier > "$fichiertemp-relatif.$extension"
| [Retour à
l'accueil] |
[Retour
haut de la page] |